Tuesday, January 20, 2026
How BitMind's Self-Evolving Detection System Works
Introduction
Deepfakes, AI-generated fake images, videos, or audio, pose a serious threat by spreading misinformation and enabling scams. BitMind is an AI tool built on the Bittensor network that detects these fakes with high accuracy. What sets BitMind apart is its self-evolving system: it improves continuously through competition and fresh data. This article explains the technical details in simple language.
The system draws inspiration from Generative Adversarial Networks (GANs), where one model generates fake data and another learns to detect it. This adversarial setup creates a constant push for better performance across images, videos, and audio.
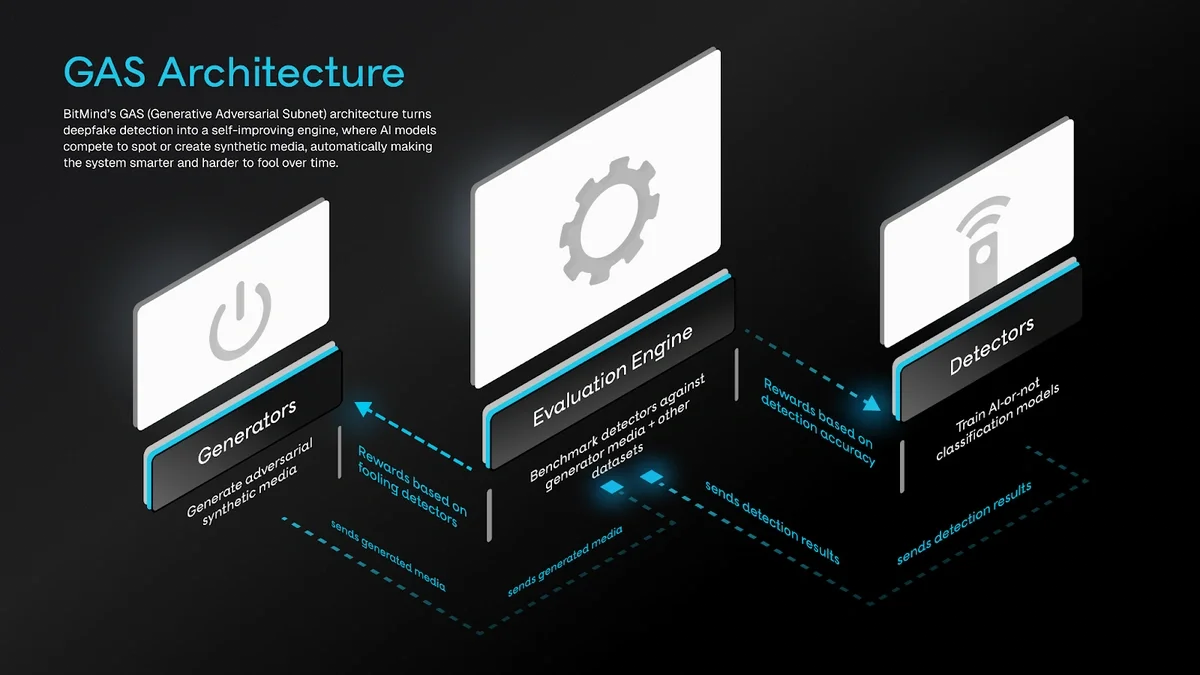
Overview of the System
BitMind operates through an adversarial framework inspired by GANs. AI engineers called miners are in a continuous competition to create the best AI detection models, and data which fools those AI detection models. There are two main types:
-
Discriminative miners submit detection models that classify media as real or fake.
-
Generative miners create synthetic (AI-generated) media to challenge the detectors.
Validators act as referees. They test the miners' submissions rigorously and determine rewards for the best performers.
The system combines multiple data sources for training and testing. This ensures models handle diverse, real-world scenarios. Every week, the top detection models are selected and integrated into BitMind's main system, giving it a significant speed advantage over competitors.
Adversarial Generated Data from Miners
The core strength comes from adversarial data: fakes specifically designed to be difficult to detect. Generative miners produce this content.
Here is how it works:
-
Validators send prompts (e.g., "generate a realistic video of a person speaking with a mario-kart t-shirt").
-
Generative miners use state-of-the-art (SOTA) generative models to create synthetic images, videos, or audio.
-
Validators perform verification check that data matches description and is of high quality
-
These synthetic samples are then evaluated by discriminative miners.
-
If the fakes are hard to detect, the generative miners earn higher rewards, encouraging continuous improvement.
To ensure miners are truly using advanced SOTA models (and not cheating with low-quality or real data), BitMind incorporates C2PA (Coalition for Content Provenance and Authenticity) standards and verification techniques. C2PA adds cryptographic metadata to generated content, proving its origin and creation process. Validators check these signatures and provenance info during evaluation. This confirms the media was produced by legitimate generative pipelines, maintaining the integrity of the adversarial loop.
This high-quality synthetic data is shared openly on Hugging Face under the "gasstation" organization. Datasets like generated-videos (over 200,000 items) and generated-images (over 600,000 items) provide the latest adversarial examples for training detectors.
Massive Open Source Datasets
BitMind builds a strong base by incorporating a vast collection of large, publicly available open-source datasets. These provide millions of real, synthetic, and semisynthetic examples across images, videos, and audio for initial training and broad benchmarking.
The full list comes from the gasbench configuration files in the BitMind-AI/gasbench repository.
Many of these datasets are preprocessed and hosted on Hugging Face under the bitmind organization or gasstation, with collections like Subnet 34 Datasets and Real Image Datasets.
Here are the key categories and examples (with Hugging Face links where applicable):
Image Datasets
These include real photos, synthetic AI-generated images, and semisynthetic manipulations (e.g., face swaps).
-
Synthetic examples:
-
gasstation-generated-images → https://huggingface.co/gasstation/gs-images-v2
-
ideogram-27k → https://huggingface.co/bitmind/ideogram-27k
-
Dalle-3-1M → https://huggingface.co/bitmind/Dalle-3-1M
-
SFHQ parts 1-4 → https://huggingface.co/bitmind/SyntheticFacesHQ
-
journeydb → https://huggingface.co/bitmind/JourneyDB
-
genimage-midjourney → https://huggingface.co/bitmind/GenImage_MidJourney
-
aura-imagegen → https://huggingface.co/bitmind/bm-aura-imagegen
-
imagine-grok → https://huggingface.co/bitmind/bm-imagine
-
fakeclue variants (e.g., fakeclue-fake-chameleon) → https://huggingface.co/bitmind/FakeClue
-
pica-100k → https://huggingface.co/Andrew613/PICA-100K
-
text-to-image-2m → https://huggingface.co/jackyhate/text-to-image-2M
-
nano-banana-150k → https://huggingface.co/bitmind/Nano-banana-150k
-
klingai-images → https://huggingface.co/bitmind/klingai-images
-
-
Real examples:
-
flickr30k → https://huggingface.co/nlphuji/flickr30k
-
fashionpedia → https://huggingface.co/detection-datasets/fashionpedia
-
megalith-10m → https://huggingface.co/drawthingsai/megalith-10m
-
eidon-image → https://huggingface.co/bitmind/bm-eidon-image
-
celeb-a-hq → https://huggingface.co/bitmind/celeb-a-hq
-
ffhq-256 → https://huggingface.co/bitmind/ffhq-256
-
ms-coco-unique → https://huggingface.co/bitmind/MS-COCO-unique-256
-
open-image-v7 → https://huggingface.co/bitmind/open-image-v7-256
-
And many more (caltech-256/101, dtd-textures, idoc-mugshots, cosyn-400k, retrievatar, medvision, food101, mmmu, pubmedvision, MMMG, wikiart, OpenScene).
-
-
Semisynthetic: face-swap → https://huggingface.co/bitmind/face-swap; bananamark-dataset → https://huggingface.co/Rapidata/bananamark-dataset
These datasets cover diverse domains like faces, fashion, medical imaging, and everyday scenes, ensuring models learn robust patterns.
Video Datasets
These focus on dynamic content with real footage, AI-generated clips, and edited semisynthetic videos.
-
Synthetic examples:
-
gasstation-generated-videos → https://huggingface.co/gasstation/gs-videos-v2
-
aura-video → https://huggingface.co/bitmind/aura-video
-
aislop-videos → https://huggingface.co/bitmind/aislop-videos
-
fakeparts variants → https://huggingface.co/hi-paris/FakeParts
-
deepaction variants → https://huggingface.co/faridlab/deepaction_v1
-
klingai-videos → https://huggingface.co/bitmind/klingai-videos
-
vidprom → https://huggingface.co/bitmind/VidProM
-
And others like senorita variants, VideoUFO, etc.
-
-
Real examples:
-
eidon-video → https://huggingface.co/bitmind/bm-eidon-video
-
dfd-real → Related to deep-fake-detection datasets
-
moments-in-time → https://huggingface.co/Pai3dot14/Moments_in_Time_Raw_50k
-
ucf101-fullvideo → https://huggingface.co/bitmind/UCF101Fullvideo
-
And more (physics-101, soccernet, etc.).
-
-
Semisynthetic: semisynthetic-video → https://huggingface.co/bitmind/semisynthetic-video; dfd-fake, lovora-fake, etc.
Audio Datasets
These handle speech deepfakes, with high-quality real speech and synthetic TTS voices.
-
Real examples:
-
common-voice-17 → https://huggingface.co/fixie-ai/common_voice_17_0
-
voxpopuli → https://huggingface.co/facebook/voxpopuli
-
gigaspeech → https://huggingface.co/speechcolab/gigaspeech
-
peoples-speech → https://huggingface.co/MLCommons/peoples_speech
-
And others like ami-corpus, crema-d.
-
-
Synthetic examples:
-
arabic-deepfake → https://huggingface.co/DeepFake-Audio-Rangers/Arabic_Audio_Deepfake
-
elevenlabs variants (various sources)
-
ShiftySpeech → https://huggingface.co/ash56/ShiftySpeech
-
And more like emovoice-db, ultravoice-cjk.
-
Estimated Scale of the Benchmark
The gasbench configuration pulls from dozens of large-scale sources, creating one of the most comprehensive deepfake detection benchmarks available. Rough estimates (conservative, based on standard dataset sizes, config multipliers, and public descriptions):
-
Images: ~15–25+ million total samples Major contributors include megalith-10m (~10-12 million real photos from Flickr), text-to-image-2m (~2 million synthetic pairs), Dalle-3-1M variants (~1 million+ high-quality synthetic), gasstation-generated-images (hundreds of thousands synthetic), nano-banana-150k (150k), FakeClue (~100k+), plus standard real ones like Open Images, MS-COCO, CelebA-HQ (~30k), FFHQ (~70k), Flickr30k (~30k), and numerous synthetic mirrors/parts.
-
Videos: ~100,000–500,000+ clips Includes large synthetic sets like gasstation-generated-videos (hundreds of thousands), deepaction (~2.6k but many variants), fakeparts (thousands across categories), klingai/vidprom (thousands), and real benchmarks like Moments in Time (50k+), UCF101, plus holdouts/user contributions.
-
Audio files: ~Several million clips (equivalent to tens of thousands of hours) Dominated by massive real corpora like Common Voice 17.0 (~31,000 hours total recorded, millions of short clips across 100+ languages), GigaSpeech (10,000 hours labeled high-quality audio), People's Speech (large-scale), VoxPopuli, plus numerous synthetic TTS/deepfake sets (ElevenLabs variants, ShiftySpeech ~3,000 hours equivalent, etc.).
This enormous scale (tens of millions of multimodal samples overall) gives BitMind a huge advantage in training robust, generalizable detectors that perform well on diverse real-world deepfakes.
Holdout Datasets Collected and Labeled from Users
In addition to generated and public data, BitMind maintains "holdout" datasets for unbiased evaluation. These are kept separate from regular training to prevent overfitting.
Users contribute by uploading suspicious media through the BitMind app or extension. Community or expert labeling determines if the content is real or fake. On Hugging Face under "bitmind", you can find related collections, including real videos and labeled sets.
Technically, holdouts serve as a final benchmark. Validators test detection models on thousands of these samples, measuring precision (avoiding false alarms) and recall (catching most fakes). This user-sourced approach keeps the system aligned with emerging real-world threats.
The Evolving Winner-Take-All Competition
The system runs on a winner-take-all basis: the highest-performing miners receive the majority of rewards. This drives intense competition.
The process:
-
Miners register their models on the Bittensor network.
-
Validators run challenges, mixing real, synthetic, and semisynthetic data from the benchmarks above.
-
Performance is scored on metrics like accuracy, robustness against hard fakes, and inference speed.
-
Top models win rewards and get deployed weekly as BitMind's updated detection engine.
This creates rapid velocity. BitMind adapts to new generative techniques in days or weeks, far faster than traditional centralized systems. The open-source bitmind-subnet repo on GitHub provides the code details, including validation logic and model handling with libraries like PyTorch.
Conclusion
BitMind's self-evolving detection system transforms deepfake defense into a dynamic, community-powered ecosystem. By leveraging GAN-inspired adversarial generation (with C2PA verification for integrity), an extensive suite of open-source datasets across images, videos, and audio, user-contributed holdouts, and a weekly winner-take-all update cycle, it maintains a leading edge in accuracy and speed.
Developers can explore the bitmind-subnet repo and gasbench configs for implementation details. For users, the key takeaway is clear: BitMind does not just detect deepfakes today; it evolves daily to stay ahead of tomorrow's threats.